To use the MLflow R API, you must install the MLflow Python package.
pip install mlflowOptionally, you can set the MLFLOW_PYTHON_BIN and
MLFLOW_BIN environment variables to specify the Python and
MLflow binaries to use. By default, the R client automatically finds
them using Sys.which("python") and
Sys.which("mlflow").
export MLFLOW_PYTHON_BIN=/path/to/bin/python
export MLFLOW_BIN=/path/to/bin/mlflowInstall mlflow as follows:
devtools::install_github("mlflow/mlflow", subdir = "mlflow/R/mlflow")Install the mlflow package as follows:
devtools::install_github("mlflow/mlflow", subdir = "mlflow/R/mlflow")Then install the latest released mlflow runtime.
However, currently, the development runtime of mlflow is
also required; which means you also need to download or clone the
mlflow GitHub repo:
git clone https://github.com/mlflow/mlflowAnd upgrade the runtime to the development version as follows:
# Upgrade to the latest development version
pip install -e <local github repo>MLflow Tracking allows you to logging parameters, code versions, metrics, and output files when running R code and for later visualizing the results.
MLflow allows you to group runs under experiments, which can be
useful for comparing runs intended to tackle a particular task. You can
create and activate a new experiment locally using mlflow
as follows:
library(mlflow)
mlflow_set_experiment("Test")Then you can list view your experiments from MLflows user interface by running:
mlflow_ui()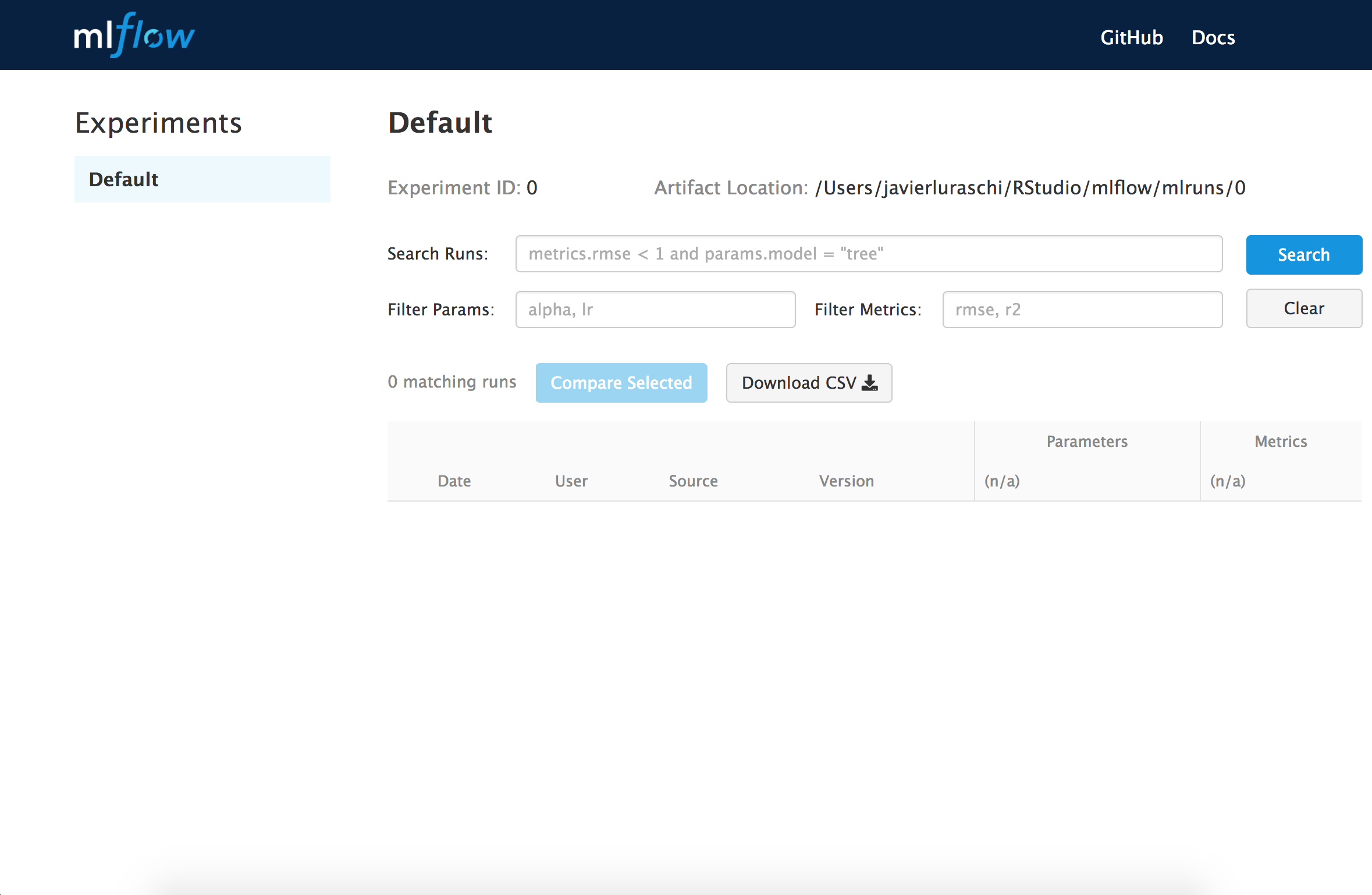
You can also use a MLflow server to track and share experiments, see running a tracking server, and then make use of this server by running:
mlflow_set_tracking_uri("http://tracking-server:5000")Once the tracking url is defined, the experiments will be stored and tracked in the specified server which others will also be able to access.
An MLflow Project is a format for packaging data science code in a reusable and reproducible way.
MLflow projects can be explicitly
created or implicitly used by running R with
mlflow from the terminal as follows:
mlflow run examples/r_wine --entry-point train.RNotice that is equivalent to running from
examples/r_wine,
Rscript -e "mlflow::mlflow_source('train.R')"and train.R performing training and logging as
follows:
library(mlflow)
# read parameters
column <- mlflow_log_param("column", 1)
# log total rows
mlflow_log_metric("rows", nrow(iris))
# train model
model <- lm(
Sepal.Width ~ x,
data.frame(Sepal.Width = iris$Sepal.Width, x = iris[,column])
)
# log models intercept
mlflow_log_metric("intercept", model$coefficients[["(Intercept)"]])You will often want to parameterize your scripts to support running
and tracking multiple experiments. You can define parameters with type
under a params_example.R example as follows:
library(mlflow)
# define parameters
my_int <- mlflow_param("my_int", 1, "integer")
my_num <- mlflow_param("my_num", 1.0, "numeric")
# log parameters
mlflow_log_param("param_int", my_int)
mlflow_log_param("param_num", my_num)Then run mlflow run with custom parameters as
follows
mlflow run tests/testthat/examples/ --entry-point params_example.R -P my_int=10 -P my_num=20.0 -P my_str=XYZ
=== Created directory /var/folders/ks/wm_bx4cn70s6h0r5vgqpsldm0000gn/T/tmpi6d2_wzf for downloading remote URIs passed to arguments of type 'path' ===
=== Running command 'source /miniconda2/bin/activate mlflow-da39a3ee5e6b4b0d3255bfef95601890afd80709 && Rscript -e "mlflow::mlflow_source('params_example.R')" --args --my_int 10 --my_num 20.0 --my_str XYZ' in run with ID '191b489b2355450a8c3cc9bf96cb1aa3' ===
=== Run (ID '191b489b2355450a8c3cc9bf96cb1aa3') succeeded ===Run results that we can view with mlflow_ui().
An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools—for example, real-time serving through a REST API or batch inference on Apache Spark. They provide a convention to save a model in different “flavors” that can be understood by different downstream tools.
To save a model use mlflow_save_model(). For instance,
you can add the following lines to the previous train.R
script:
# train model (...)
# save model
mlflow_save_model(
crate(~ stats::predict(model, .x), model)
)And trigger a run with that will also save your model as follows:
mlflow run train.REach MLflow Model is simply a directory containing arbitrary files, together with an MLmodel file in the root of the directory that can define multiple flavors that the model can be viewed in.
The directory containing the model looks as follows:
dir("model")## [1] "crate.bin" "MLmodel"and the model definition model/MLmodel like:
cat(paste(readLines("model/MLmodel"), collapse = "\n"))## flavors:
## crate:
## version: 0.1.0
## model: crate.bin
## time_created: 18-10-03T22:18:25.25.55
## run_id: 4286a3d27974487b95b19e01b7b3caabLater on, the R model can be deployed which will perform predictions
using mlflow_rfunc_predict():
mlflow_rfunc_predict("model", data = data.frame(x = c(0.3, 0.2)))## Warning in mlflow_snapshot_warning(): Running without restoring the
## packages snapshot may not reload the model correctly. Consider running
## 'mlflow_restore_snapshot()' or setting the 'restore' parameter to 'TRUE'.
## 3.400381396714573.40656987651099
## 1 2
## 3.400381 3.406570MLflow provides tools for deployment on a local machine and several production environments. You can use these tools to easily apply your models in a production environment.
You can serve a model by running,
mlflow rfunc serve modelwhich is equivalent to running,
Rscript -e "mlflow_rfunc_serve('model')"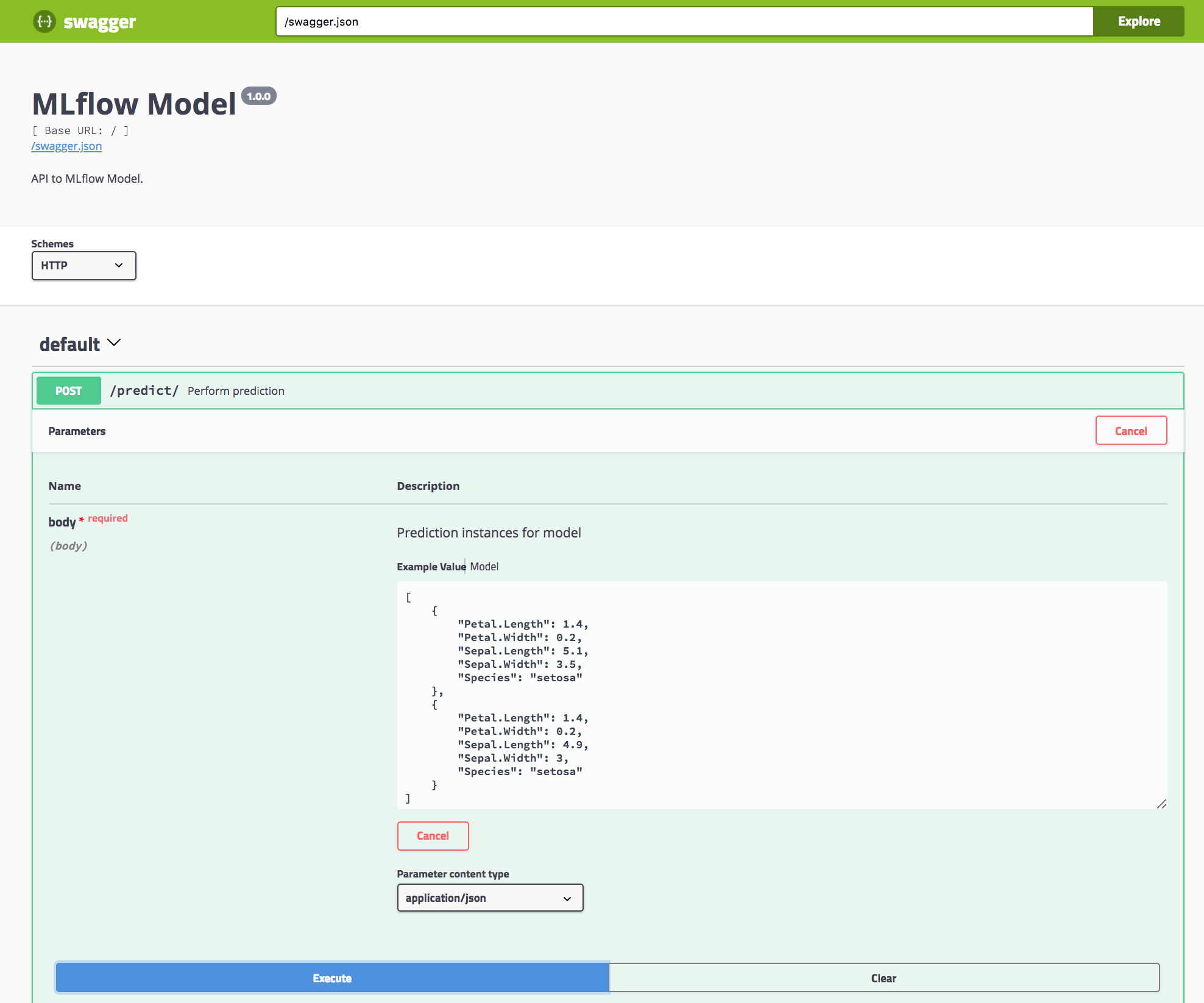
You can also run:
mlflow rfunc predict model data.jsonwhich is equivalent to running,
Rscript -e "mlflow_rfunc_predict('model', 'data.json')"When running a project, mlflow_snapshot() is
automatically called to generate a r-dependencies.txt file
which contains a list of required packages and versions.
However, restoring dependencies is not automatic since it’s usually an expensive operation. To restore dependencies run:
mlflow_restore_snapshot()Notice that the MLFLOW_SNAPSHOT_CACHE environment
variable can be set to a cache directory to improve the time required to
restore dependencies.
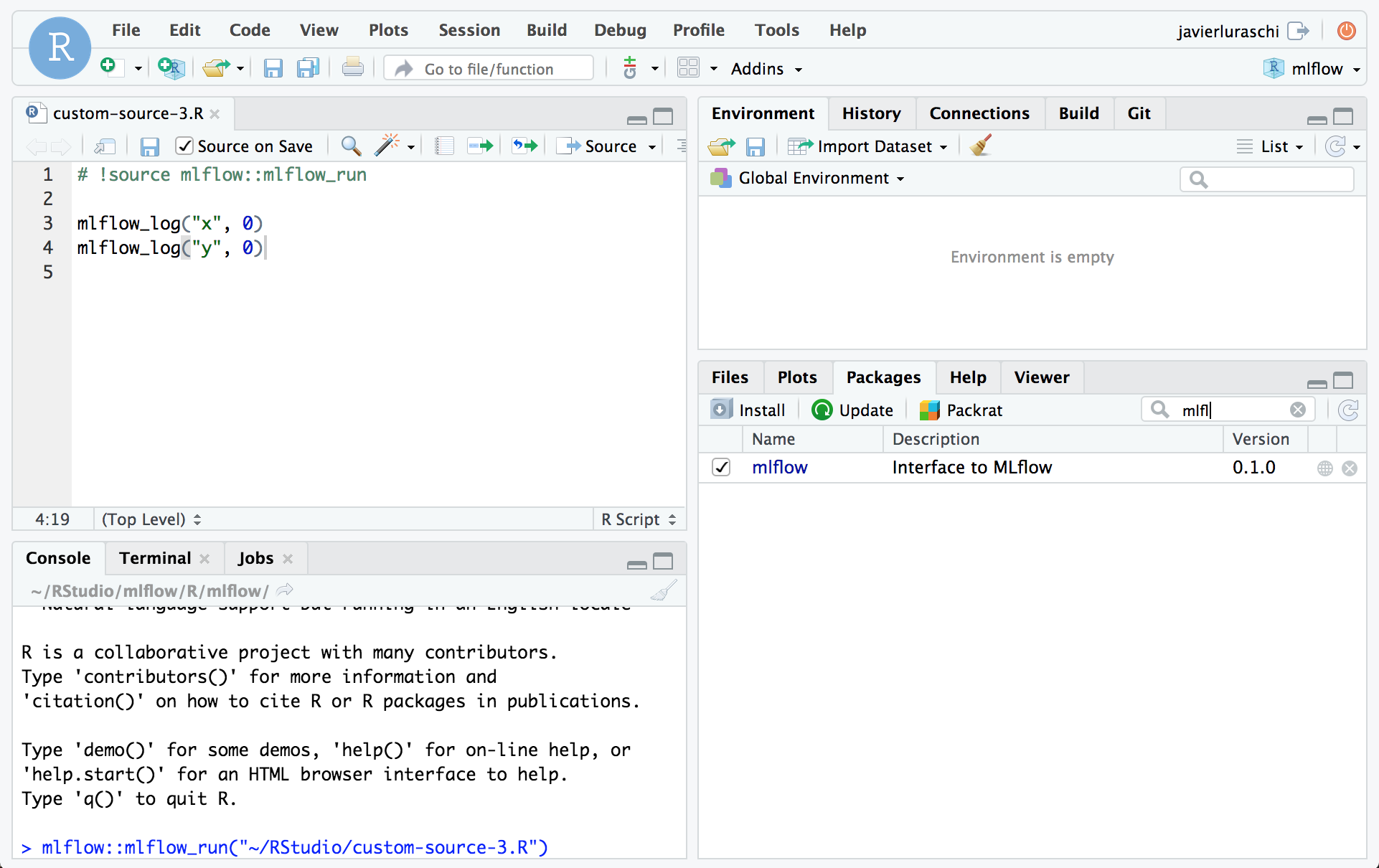
To enable fast iteration while tracking with MLflow improvements over
a model, RStudio 1.2.897 an
be configured to automatically trigger mlflow_run() when
sourced. This is enabled by including a
# !source mlflow::mlflow_run comment at the top of the R
script as follows:
See the MLflow contribution guidelines.